Geschrieben von everflux am Juni 22nd, 2008
Google hat ein neues Produkt online. Beta, wie üblich. Diesmal werden „anonymisierte“ Daten über Webseiten via Google Trends veröffentlicht.
Das erlaubt einem schon ganz gute Einblicke in den Markt. Auch gibt es einen kleinen Einblick in die Möglichkeiten, die Google oder andere Datensammler mit den erhobenen Daten bekommen.
Nachdenklich sollte Google Trends for Websites auch im Hinblick auf die Voratsdatenspeicherung machen: An viele Möglichkeiten der Auswertung denkt man zum Zeitpunkt der Erhebung nicht. Das gilt auch für „loyalty“ Programme wir Miles and More oder Payback. Den üblichen Verweis auf Orwell erspare ich mir.
Hier die – wenigen – Daten zu diesem Blog: everflux.de Trends
Etwas aufschlußreicher ist ein Blick auf mein allseits geliebtes Lawblog: lawblog.de Trends
Der typische Lawblog Leser ist also ein grüner Taxi-interessierter der sich neben Rechtsthemen aber auch für andere top-blogs interessiert.
Nimmt man dann noch hinzu, dass Google bemüht ist, Suchabfragen einen „Sinn“ zu geben (Google erkennt schwule und lesben), kann einem Angst und Bange werden.
Geschrieben von everflux am April 15th, 2008
Yahoo hat die Crawler Infrastruktur aktualisiert – teil davon ist Slurp 3.0, der neue Yahoo Crawler. Wie Golem berichtet hat Yahoo bisher nicht veröffentlicht, welche Aktualisierungen an dem Crawler vorgenommen wurden.
Dies ist kein unübliches Vorgehen, lediglich als Google seinen Crawler beigebracht hat, gzip Inhalte zu verstehen, oder die Crawler an einen gemeinsamen Cache angeschlossen hatte, um doppeltes Crawlen zu vermeiden, wurde dies publik gemacht. Bei Yahoo steht eine Umstellung auf Hadoop an – die Zukunft lautet bei Yahoo immer stärker OpenSource und Java. Sicherlich nicht schlecht für die Community, zudem zeigt es deutlich, dass Java alles andere als „langsam“ ist. Nachdem Yahoo auf einigen Seiten für 20% und mehr des Traffiks verantwortlich war, da der Crawler wild auf content war, könnte dieses unerwünschte Phänomen mit dem Slurp 3.0 nun der Vergangenheit angehören.
Geschrieben von everflux am Februar 18th, 2008
Google, der Mr. „Don’t be/do evil“ macht jetzt Referrer-Spam, um Cloaker zu enttarnen. Ist schon länger bekannt – aber was es hiermit aufsich hat, das ist mir noch etwas unklar:
Der Versuch heute webalizer oder webdruid Statistiken vernünftig zu lesen wurde hinfällig, denn hunderte Requests dieser Sorte machen die Auswertung von Suchanfragen per Referrer kaputt: Weiterlesen »
Geschrieben von everflux am Januar 10th, 2008
Für alle die eine „Suchmaschine“ bauen – es gibt ein paar klitzekleine Verhaltensregeln, die man beachten sollte.
Ein Beispiel:
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /feed/ HTTP/1.1" 200 15773 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /feed/rss/ HTTP/1.1" 200 9052 "http://www.newskraft.de" "Newskraft.de" 1 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /feed/atom/ HTTP/1.1" 200 15021 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /?p=470&akst_action=share-this HTTP/1.1" 200 4908 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /?p=469&akst_action=share-this HTTP/1.1" 200 5049 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /?p=468&akst_action=share-this HTTP/1.1" 200 4644 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:46 +0100] "GET /?p=467&akst_action=share-this HTTP/1.1" 200 4828 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:47 +0100] "GET /?p=465&akst_action=share-this HTTP/1.1" 200 6963 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:47 +0100] "GET /?p=464&akst_action=share-this HTTP/1.1" 200 5003 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:47 +0100] "GET /?p=462&akst_action=share-this HTTP/1.1" 200 4847 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:47 +0100] "GET /?p=461&akst_action=share-this HTTP/1.1" 200 7506 "http://www.newskraft.de" "Newskraft.de" 0 everflux.de
78.46.45.99 - - [10/Jan/2008:21:28:47 +0100] "GET /?p=463&akst_action=share-this HTTP/1.1" 200 9277 "http://www.newskraft.de" "Newskraft.de" 1 everflux.de
Man beachte die Zeiten, wann die Zugriffe stattfanden.
Und das war noch lange nicht das Ende. Also wenns denn schon ein Crawler sein soll, dann nicht mehr als einen Zugriff pro Sekunde.
Immerhin bei Newskraft lobenswert: robots.txt wird vorher geladen – wie sie genutzt wird, hab ich jedoch nicht ausprobieren wollen.
Geschrieben von everflux am Januar 10th, 2008
Normalerweise schaue ich nicht in die live Logs vom Apache Webserver des Blogs, aber aus gewissen Gründen machte ich mir doch mal die Mühe.
Was mir da gerade über den Weg gelaufen ist, finde ich doch interessant:
„Feedfetcher-Google; (+http://www.google.com/feedfetcher.html; 1 subscribers; feed-id=18021914886172537744)“
Viellicht gehört das nicht unbedingt in den Useragent – aber in jedem Fall eine sehr innovative Idee.
Da muß ich nichtmal Feedburner oder ähnliches bemühen um herauszufinden dass ich einen ganzen Leser habe 😉
Was ich nicht ganz verstehe, sind die weiteren Requests, die eine andere Feed-Id beeinhalten.
„Feedfetcher-Google; (+http://www.google.com/feedfetcher.html; 1 subscribers; feed-id=16484629274111537011)“
Aha, die antwort ist einfach: Wenn Google den Feed über verschiedene URLs kennt, so wird jedesmal eine eindeutige 64bit ID pro URL erzeugt.
Das bedeutet, man muss die Anzahl der Abbonennten zusammenzählen. Dann hab ich wohl 2. 🙂
Weitere Informationen zum Google Feedfetcher gibt es im Google Reader Help Bereich.
Geschrieben von everflux am Januar 6th, 2008
Tobi, der das seo-phpbb Projekt betreibt, ist zuversichtlich bald wieder mit der Seite online zu gehen.
Derzeit finden sich die Downloads lediglich bei Google-Code.
Besonders schön, wenn die Seite wieder online ist, gibt es auch wieder die Banner-Management und weitere Plugins, die Tobi entwickelt. Hut ab vor dem Projekt!
Wer überlegt ein PhpBB2 oder PhpBB3 zu betreiben, sollte sich unbedingt die SEO Modifikationen ansehen. Insbesondere für stark frequentierte Foren sollte PhpBB3 dank Caching den Server deutlich entlasten, und ist eine oeberlegung für derzeitige phpbb2 Foren wert.
Geschrieben von everflux am Dezember 14th, 2007
Vermutlich kennt jeder schon die Google Webmaster Tools. Und fast jeder die neuen Funktionen der Content Analyse der Google Webmaster Tools.
Ich kann die bis heute noch nicht – war ich doch lange nicht mehr in den Webmaster Tools unterwegs. Sehr schöne neue Funktionen, wie ich finde:
- Probleme mit title Tags von Webseiten (was auch immer hier käme, ich habe keine Probleme gemeldet 🙂 )
- Doppelte Meta Beschreibungen (könnte mal für duplicate content gehalten werden, zumindest wird Google hier aber eher ein Text-Snippet in den Suchergebnisseiten (SERP) anzeigen als die Meta Description
- Lange Metabeschreibungen – auch hier gilt: Eher ein Snippet als eine viel zu lange Metabeschreibung. In der kürze liegt die Würze!
- Kurze Metabeschreibungen – diese sind dann zu kurz. Nur drei oder vier Worte – das hilft auch keinem Surfer. Also auch hier wieder eher ein Snippet als die ggf. gewünschte META Description in den Suchergebnisseiten
Warum aber sind Title und Description denn so wichtig? Ganz einfach: Selbst wenn man bei Google für ein Ergebnis sehr weit oben ist (also Seite 1 und da ggf. noch „oben“) heißt es nicht, dass der User auch klickt.
Ich z.B. klicke aus Prinzip nicht auf diese extrem häßlichen Ergebnisse von cylex dem „Stadtbranchenbuch“. Die sind stets in Großbuchstaben und die Beschreibung (sic!) lädt nicht zum klicken ein.
Wenn ich anhand der Beschreibung aber schon abschätzen kann – hey die Seite ist relevant (und das macht Google auch im Vorfeld) bzw. interessant, dann klicke ich.
Und so geht es anderen auch.
Geschrieben von everflux am Dezember 2nd, 2007
Ich bin ja ein ganz großer Fan davon, wenn mir Dienstleistungen oder Artikel per E-Mail angepriesen werden. Hier haben wir es mit einem besonders seriösen Angebot zu tun, dass ich keinem vorenthalten möchte.
Vorweg die Gründe, weswegen man aus meiner Sicht solche Angebot auf gar keinen Fall annehmen sollte:
- Firma ist eine britische Ltd. – muss ich wohl nicht mehr zu sagen
- Produkt wird per Spam Mail beworben
- Opt-Out wenn man keine weiteren „Informationen“ möchte
- 105 Backlinks? Alle großen Suchmaschinen (wie Google) haben Richtlinien die genau solche „unechten“ Links verbieten
- Unrichtige Behauptungen in den Aussagen
- „Sie zahlen nur für TOP Positionierungen“
Jetzt aber zu der Offerte von preiswerte Suchmaschinenoptimierung.de
Weiterlesen »
Geschrieben von everflux am November 15th, 2007
Wer sieht den Unterschied?
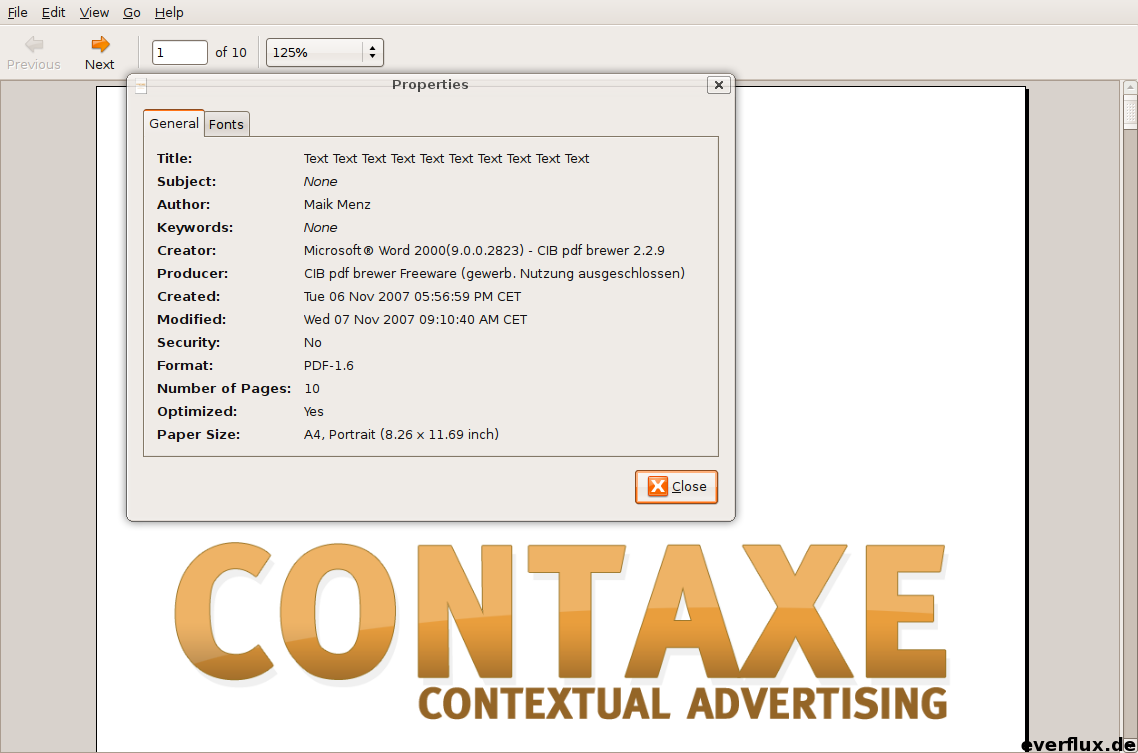
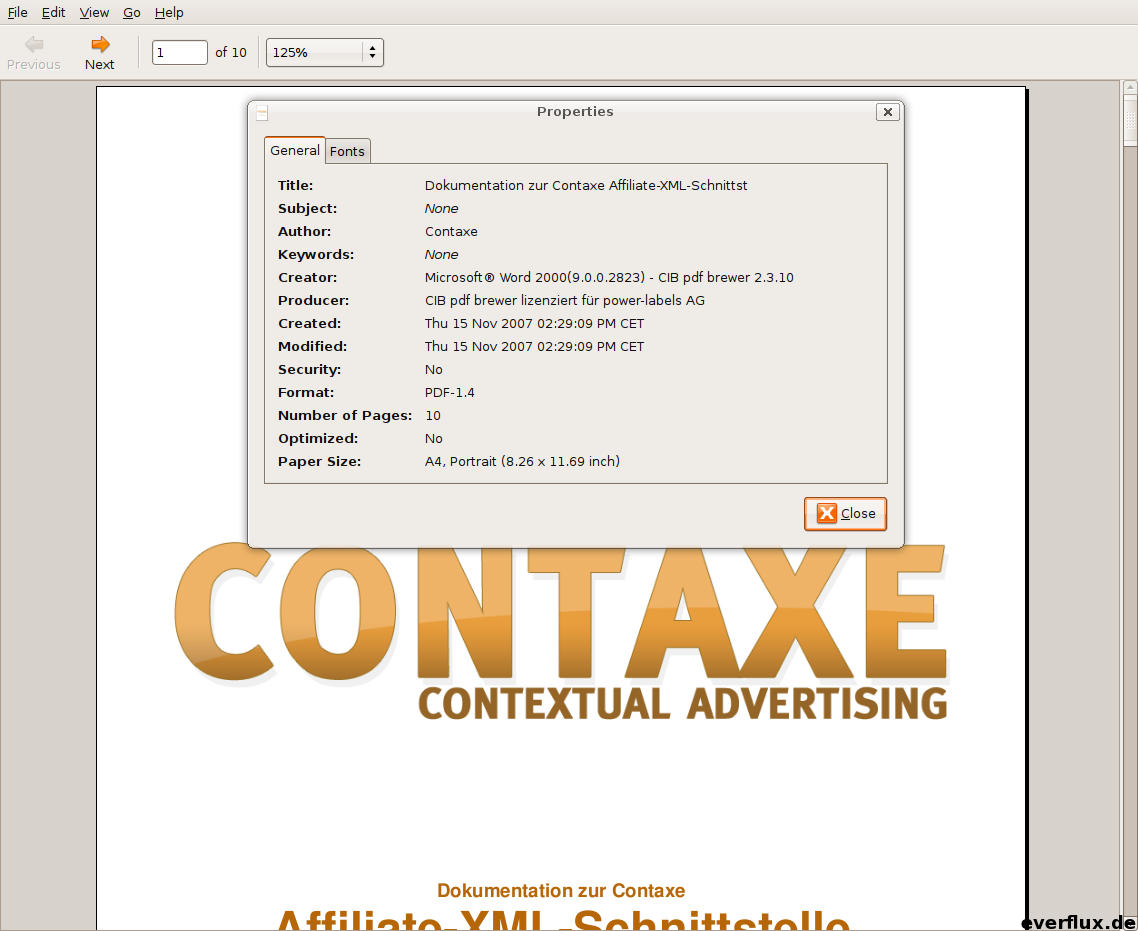
War Office 2000 nicht die letzte Version, die nicht online freigeschaltet werden mußte?
(PS: Der CIB PDF Brewer kostet für gewerblichen Einsatz 19 Euro. Richtig, nichtmal einen zwanni. Jeder kann sich ja selber überlegen wie seriös er sowas findet.)
Geschrieben von everflux am November 6th, 2007
Noch weit mehr als Google-Bot und der Yahoo Slurp Crawler zusammen hat der Host 209.249.11.3 bei mir Traffik gemacht. In den Statistiken habe ich erstmal nur die Traffiksumme gesehen und mich gefragt: Wer zum Henker…
Das Netz ist von Abovenet als Microsoft Research Subnetz mit 14 Hosts announced. Immerhin identifiziert sich der Bot auch im Useragent vernünftig:
209.249.11.3 – – [02/Nov/2007:23:31:36 +0100] „GET /resharper-jetbrains-bringt-resharper-30-fur-visualstudio-231/ HTTP/1.0“ 200 14213 „http://everflux.de/category/microsoft/“ „MSRBOT (http://research.microsoft.com/research/sv/msrbot/“ 0 everflux.de
Ich finde es schön, dass Microsoft forscht – ich sehne ein Such-Oligopol herbei, und noch vor Yahoo sehe ich bei Microsoft ein großes Potential. Was an dem Bot interessant ist: Er übermittelt ein Referrer! Damit könnte man sich einen interessanten Einblick verschaffen, wie der Bot crawlt. So haben alle was zum Forschen…

Neue Kommentare